Dependency Injection Pattern In Practice
Introduction
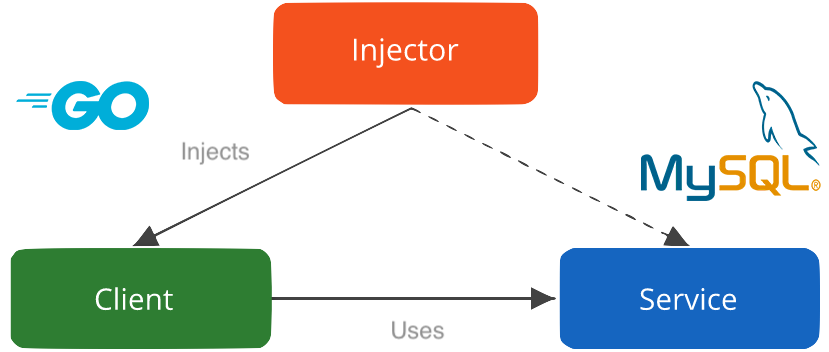
Dependency injection is a powerful pattern in any developers toolbelt. At it’s core it treats the application as a service that has different executable components that classify as it’s dependencies. These dependencies might have different data or interact with different technologies, but they are always going to be performing relatively similar actions. This allows for a decoupling of the source of the data, or the repository, from the actual implementation that interacts with the data, or the service.
Recently I tackled a small project that required compatibility with a wide array of data sources but still had a fairly similar implementation. The goal of the application was to gather data from external providers and store the parts of the data that are needed in a database more specific to the application. I wanted to take the resulting data from the database and visualize it with Grafana. The dependency injection pattern seemed like the best option to support a wide array of data providers without having to re-write the underlying business logic that implements those sources.
Jumping in
I wrote the application in Golang. I found a great tutorial on how to implement dependency injection in a Go application and got started writing my code. The service needed to run two primary functions on the supplied data source, collect() to collect all of the data from the external provider and store() to store that data in my application database. It took a pretty basic function to get this working on the service side:
// Run the data collection & storage.
func (s *DataCollectionService) Execute(ctx context.Context) error {
// Run the collect method to populate the repository
err := s.repository.collect()
if err != nil {
panic(err)
}
// Run the store method to store the repository to the database
err = s.repository.store()
if err != nil {
panic(err)
}
return nil
}
The function does two primary things, it calls to the dependency’s collect() method to collect the data and then the store() method to handle the storage of the data. With that in place, I had to write my actual dependency logic for each specific dependency.
In this application I wanted to ingest data from two different sources, an application called Sonarr and an application called Transmission (web version). Each of the dependencies implemented both the collect() and store() functions specific to the data that they were retrieving and storing.
For the Sonarr service, an API key is needed but none is needed for Transmission. I added a table to keep track of the different applications that were interacted with and the metadata that was needed for them, such as a URL and API key. The table looked like this:
| identifier | api_key | base_url | is_scanned |
|---|---|---|---|
| sonarrQueue | <api_key> | http://127.0.0.1:8989/ | 1 |
| sonarrCalendar | <api_key> | http://127.0.0.1:8989/ | 1 |
| transmission | http://127.0.0.1:9091/ | 1 |
is_scanned is used to determine whether or not to actually include the dependencies in the service execution. identifier is unique for each dependency and determines which dependency to inject into the service. api_key is an optional value for interacting with authenticated API’s. base_url is used to make the HTTP request to the API in the collect() function.
Putting it to the test
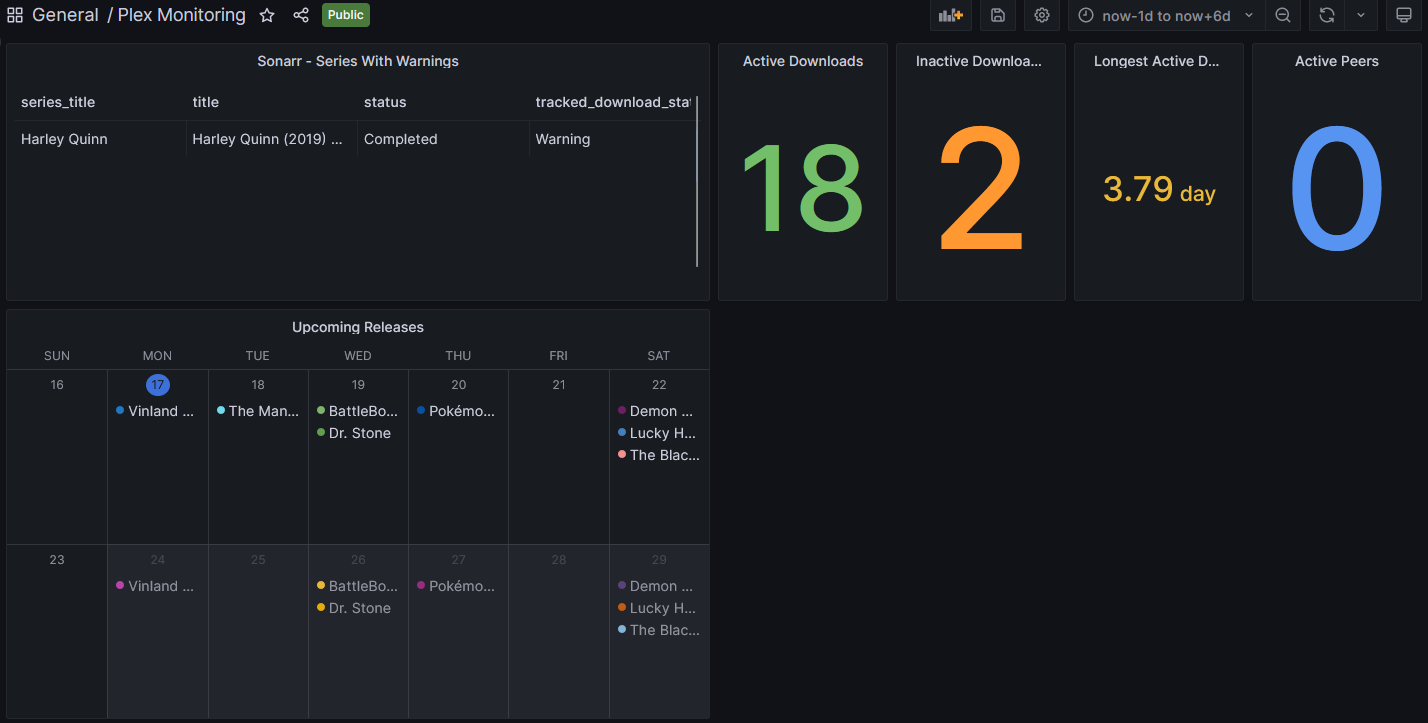
With the code written and the tables populated I ran the code to test it out. The service worked quite well and was able to execute for each of the applications it needed to interact with and store that data in the MySQL database I was using for the project. After confirming that the data was being ingested correctly I hopped over to Grafana to start visualizing it. Here’s what I ended up with:
Conclusion
Grafana was super easy to work with and with some very basic SQL queries I was able to extract the data that I needed from the project’s database and visualize it in a meaningful way. The dependency injection pattern was extremely useful for this project because it allowed me to very easily connect this application up with other applications by essentially only writing the code that was specific to interacting with the application I needed to integrate.
This project is hosted on GitHub if you’d like to peek at the source and see how you could set something similar up in your own application. If you’ve made it this far, I hope that this post helped to provide some valuable insight into how dependency injection can be used to simplify implementations that have a need for multiple repositories of data.